Ask Gordon
If you have a question about Core GRADE that you would like answered
please email guyatt@mcmaster.ca.
Core GRADE provides the essentials for using GRADE to address paired comparisons of treatments in systematic reviews, clinical practice guidelines, and health technology assessments.
Core GRADE 1, overview
Doi:10.1136/bmj-2024-081903
https://www.bmj.com/content/389/bmj-2024-081903
Core GRADE 2, target and precision
Doi:10.1136/bmj-2024-081904
https://www.bmj.com/content/389/bmj-2024-081904
Core GRADE 3, inconsistency
Doi:10.1136/bmj-2024-081905
https://www.bmj.com/content/389/bmj-2024-081905
Core GRADE 4, risk of bias
Doi:10.1136/bmj-2024-083864
https://www.bmj.com/content/389/bmj-2024-083864
Core GRADE 5, indirectness
Doi:10.1136/bmj-2024-083865
https://www.bmj.com/content/389/bmj-2024-083865
Core GRADE 6, summary of findings
Doi:10.1136/bmj-2024-083866
https://www.bmj.com/content/389/bmj-2024-083866
Core GRADE 7, evidence to decision
Doi:10.1136/bmj-2024-083867
Whenever the effect is large (and for binary outcomes this can mean a relative risk reduction greater than 30%) this means you should consider invoking the optimal information size (see https://www.bmj.com/content/389/bmj-2024-081904). The OIS is the sample size calculation that would be undertaken when planning a single randomised controlled trial. For binary outcomes, these involve specifying the acceptable error rates: α (typically 0.05) and β (typically 0.20), the control group event rate (chosen from the context), and a modest relative risk reduction, typically 20% or 25%. If the sample size is a long way from the OIS, you can rate down twice for imprecision. If the number of events is so small you are very uncertain whether there is any effect at all. If the sample size is sufficiently far from the OIS, you may consider rating down three levels for imprecision.
In planning a systematic review, reviewers must be prepared to find considerable inconsistency (heterogeneity) between studies. This variability may be in either relative effects or absolute effects.
Let’s start with differences in relative effects.
Reviewers consider patient characteristics that might modify the relative effect of the intervention (synonyms: subgroup effect, effect modification, interaction). Might the relative effect be larger in the old versus the young, those with greater versus less disease severity, or with comorbidity versus without (or in each case, vice versa: larger in the young versus the old, etc.).
In considering these possible effect modifications (synonyms: subgroup effects, interactions) reviewers remember that relative subgroup effects are much, much rarer than differences in baseline risk. Bearing that in mind, reviewers consider the direction of any effect modification that might be present. Is there a compelling biological rationale that the relative effect will be larger in the old than the young (or the opposite). Is there a compelling biological rationale that the relative effect will be larger in those with greater versus less severe disease (or the opposite). Is the reviewer ready to state explicitly the direction of their subgroup hypothesis? If they think: well, age might modify the effect, but it could go either way (bigger effect in the old or the young), they reject this candidate relative subgroup hypothesis. Similarly with disease severity or comorbidity. In other words: no compelling biological reason that dictates the direction of effect, dismiss that hypothesis. Compelling rationale for the direct, include the a prior subgroup hypothesis.
Now, let’s consider absolute effects (risk differences).
Here, reviewers think of easily identifiable patient characteristics that are likely to associated with big differences in risk of a patient-important outcome they are considering. Typical such characteristics would be age, disease severity, and presence of comorbidity. For such factors, reviewers consider whether it is plausible that an investigator – ideally in well done cohort studies, but if that’s not available, less well done cohort studies or randomized trials – might have provided data for the groups of patients (the old and the young; greater and less disease severity; with and without comorbidity). If it is plausible, and reviewers suspect differences in baseline risk might be large enough that the optimal action (and in a guideline the recommendations) might differ for the different groups of patients, they includes this as an a priori hypothesis and seek the evidence.
The upshot of this process is that it is more likely that reviewers will have one or more hypotheses about the impact of baseline risk on magnitude of effect than hypotheses about relative effect. It is possible, that the same variable will generate a hypothesis about baseline risk (for instance larger baseline risk unvaccinated patients with COVID) and a hypothesis about relative effect modification (larger relative effect of nirmatrelvir-ritonavir in the unvaccinated).
The first step in deciding whether to rate down for imprecision is to decide what it is in which we are rating our certainty – that is, the target of certainty rating. The process of deciding on the target begins with setting a threshold. Using Core GRADE, the two possible thresholds are the null and the minimally important difference (MID). This answer addresses the choice of the null.
When one chooses the null as the threshold, one begins by rating the certainty in a non-zero effect (i.e. that is the target). If the point estimate clearly represents a non-zero effect, one then examines the confidence interval to see whether it overlaps the chosen threshold, the null. When there is such an overlap, one will always rate down for imprecision at least once. So, that’s settled, and the only remaining issue is whether one rates down once or twice. Deciding whether to rate down once or twice involves a judgement of whether, considering imprecision alone, one would conclude “the intervention probably provides a non-zero effect” (in this case a non-zero benefit) or whether the more appropriate conclusion is less certain “the intervention possibly provides a non-zero effect”.
This is a matter of intuitive judgment regarding the message one feels is most appropriate for one’s target audience. Personally, I am reluctant to convey the “probably” message when there is a substantial possibility of harm, and a reasonable threshold for substantial probability might be a 10% increase in relative risks. Anything over a 10% increase in the relative risk of harm would then warrant rting down twice.
However, as Core GRADE 1 emphasizes, one must ultimately step back and take a gestalt look at the final certainty rating. If one had already decided to rate down for one of the other domains, then the best possible certainty rating would be low, and rating down twice for imprecision would result in a rating of very low. Looking at the whole picture of the evidence, one may feel that low is the more appropriate certainty rating rather than very low. If that were the case, then rating down only once for imprecision would be the way to ensure the most appropriate final certainty rating.
Barring compelling evidence of publication bias, we conclude “undetected” (the usual situation). If all the small number of studies were funded by the pharmaceutical industry and the studies are small, one would seriously consider rating down for publication bias.
https://www.bmj.com/content/389/bmj-2024-083864Let’s say that a guideline panel faces a situation in which there is obvious differences in baseline risk that would mandate different recommendations for groups of patients at different risk. A quick look finds no systematic reviews of prognosis available, and the group doesn’t have the time or resources to conduct such a review. They should certainly check to see if the randomized trials provide the information, but they usually will not. What should they do then?
My answer is that they should take an expedited look at the information that is available from observational studies of prognosis. They would find one or more studies that would identify one or more key prognostic factors on which to make their judgment.
Consider for instance a panel making a recommendation regarding use of nirmatrelvir-ritonavir for acute COVID in 2025. The vast majority of patients are at sufficiently low risk of severe illness and hospitalization that they do not need the drug. On the other hand, immunosuppressed individuals are at high enough risk that they should. There may be groups of patients with multimorbidity who are in between, and who may or may not receive overall net benefit by drug use.
Such a panel would be very unwise to issue a single recommendation for all groups. If they did not have the resources or time to do the systematic review, they would conduct a less systematic review of the limited prognostic information available and proceed according to the results.
Regarding distinguishing between prognostic factors (in the context of treatment effects, baseline risk) and effect modification (synonyms subgroup effect, interaction), I have an exercise that may help. The slide below depicts three scenarios. For each, you need to say whether age is a prognostic factor (clue, look at the control group), an effect modifier (synonyms relative subgroup effect, interaction), or both prognostic factor and effect modifier.
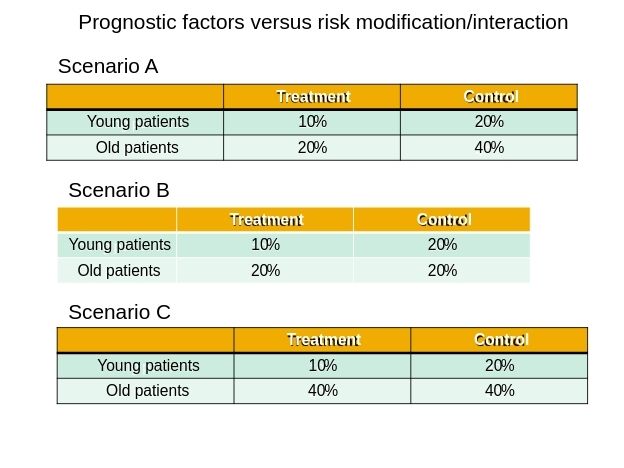
In scenario A, looking at the control group, age is a prognostic factor: old patients die twice as often as young patients. The baseline risk of dying in the old is twice that in the young. In this scenario, age is not an effect modifier: the effect of treatment in both old and young is to cut the risk of dying in half (50% relative risk reduction).
In scenario B, looking at the control group, age is a not a prognostic factor: old and young patients have the same risk of dying. The baseline risk in both groups is the same. In this scenario, age is an effect modifier: in young patients treatment cuts the risk of dying in half (50% relative risk reduction) while it has no impact on risk in the old (relative risk 1.0).
In scenario C, looking at the control group, age is a prognostic factor: old patients die twice as often as young patients. The baseline risk of dying in the old is twice that in the young. In this scenario, age is also an effect modifier: in young patients treatment cuts the risk of dying in half (50% relative risk reduction) while it has no impact on risk in the old (relative risk 1.0).
Prognosis has to do with patient characteristics that are associated with outcomes of interest. For instance, older age, severe disease, and lower socioeconomic status are all typically associated with prognosis. Patients are often interested in their prognosis: how quickly will I recover from this injury? with my new cancer diagnosis, how long do I have to live.
The issue of baseline risk in the context of guidelines is a particular application of prognostic information. Given that relative effects are almost always similar across prognostic categories (and thus across baseline risk) absolute treatment effects will be greater in the old than the young, those more severely versus less severely diseased, and those who are poorer than richer. That is, patients with poorer prognosis will have larger treatment effects than those with better prognosis. Given the resultant greater net benefit, we are more likely to recommend treatment to the older, sicker, and poorer.
Should the consideration of baseline risk form an independent prognostic question for a guideline, or is it a subsidiary issue in each PICO that all guidelines should consider (even if the guideline does not focus on prognosis)? The answer is yes: all guideline panels should bear in mind issues of baseline risk (that is, issues of prognosis) and it is thus a potential independent prognostic question in each guideline recommendation. And yes, baseline risk/prognosis is a subsidiary or secondary issue that all guidelines consider even if their focus is not on prognosis.